
Runchu Tian (田润初)
Incoming PhD Student @ UNC-Chapel Hill

Hi! This is Runchu.
I will be joining Prof. Mohit Bansal’s Group at UNC-Chapel Hill as a PhD student in Fall 2026, working on Multimodal LLMs.
I am curretly a second year MS student advised by Prof. Jiawei Han on LLM related topics. I earned my Bachelor Degree from Tsinghua Unversity, where I was advised by Prof. Zhiyuan Liu on LLM agents.
Feel free to contact me for collaborations, connections, or any questions you may have whether by email (runchut2[at]illinois.edu) or through social media. Thank you!
Publications (2023.6 - present)
- ACL’25
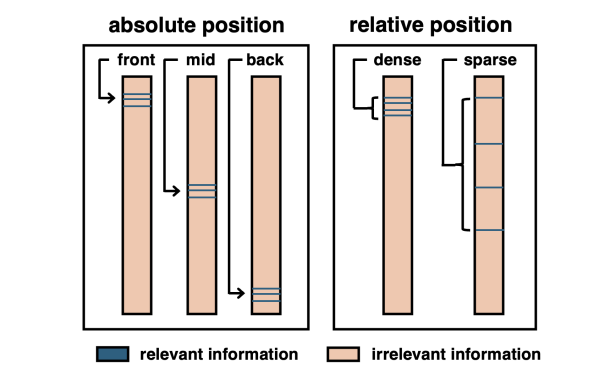 Distance between Relevant Information Pieces Causes Bias in Long-Context LLMsRunchu Tian*, Yanghao Li*, Yuepeng Fu, Siyang Deng, Qinyu Luo, Cheng Qian, Shuo Wang, Xin Cong, Zhong Zhang, Yesai Wu, Yankai Lin, Huadong Wang, and Xiaojiang Liu
Distance between Relevant Information Pieces Causes Bias in Long-Context LLMsRunchu Tian*, Yanghao Li*, Yuepeng Fu, Siyang Deng, Qinyu Luo, Cheng Qian, Shuo Wang, Xin Cong, Zhong Zhang, Yesai Wu, Yankai Lin, Huadong Wang, and Xiaojiang Liu
*Equal contributionIn Findings of the Association for Computational Linguistics: ACL 2025Positional bias in large language models hinders their ability to effectively process long inputs. A prominent example is the "lost in the middle" phenomenon, where LLMs struggle to utilize relevant information situated in the middle of the input. While prior research primarily focuses on single pieces of relevant information, real-world applications often involve multiple relevant information pieces. To bridge this gap, we present LongPiBench, a benchmark designed to assess positional bias involving multiple pieces of relevant information. It includes various tasks and input lengths. Thorough experiments are conducted with three commercial and six open-source models. These experiments reveal that while most current models are more robust against the "lost in the middle" issue, there also exist noticeable biases related to the spacing of relevant information pieces. These findings highlight the importance of evaluating and reducing positional biases for long-context LLMs.
@inproceedings{tian2025distance, title = {Distance between Relevant Information Pieces Causes Bias in Long-Context LLMs}, author = {Tian*, Runchu and Li*, Yanghao and Fu, Yuepeng and Deng, Siyang and Luo, Qinyu and Qian, Cheng and Wang, Shuo and Cong, Xin and Zhang, Zhong and Wu, Yesai and Lin, Yankai and Wang, Huadong and Liu, Xiaojiang}, year = {2025}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2025}, } - ACL’24
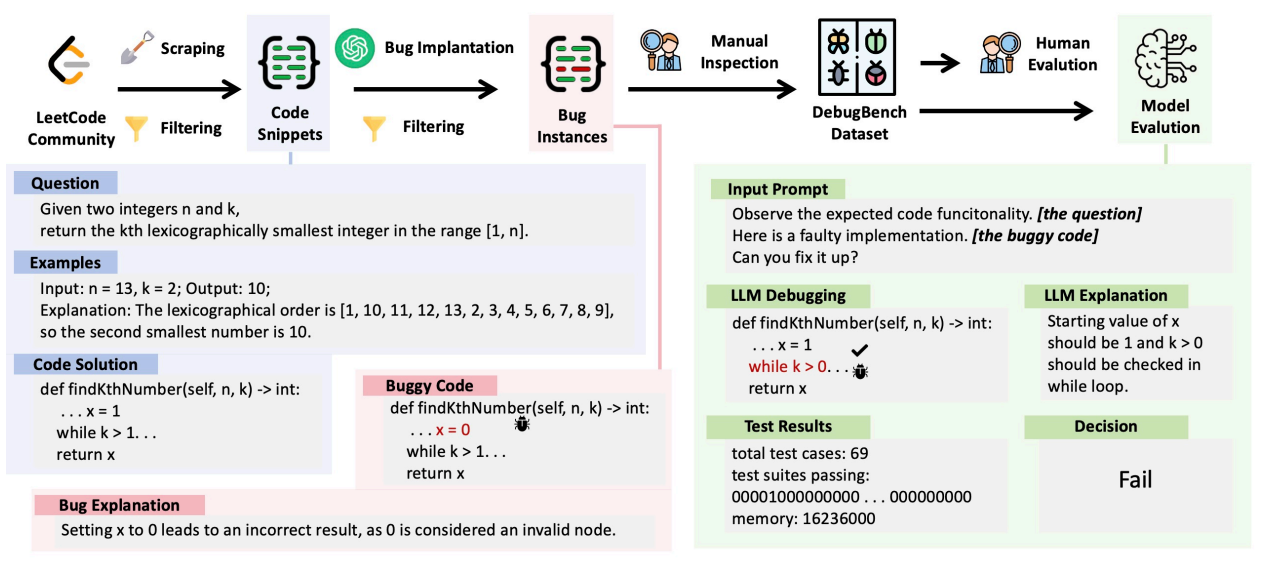 DebugBench: Evaluating Debugging Capability of Large Language ModelsRunchu Tian*, Yining Ye*, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Haotian Hui, Weichuan Liu, Zhiyuan Liu, and Maosong Sun
DebugBench: Evaluating Debugging Capability of Large Language ModelsRunchu Tian*, Yining Ye*, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Haotian Hui, Weichuan Liu, Zhiyuan Liu, and Maosong Sun
*Equal contributionIn Findings of the Association for Computational Linguistics: ACL 2024Large Language Models (LLMs) have demonstrated exceptional coding capability. However, as another critical component of programming proficiency, the debugging capability of LLMs remains relatively unexplored. Previous evaluations of LLMs’ debugging ability are significantly limited by the risk of data leakage, the scale of the dataset, and the variety of tested bugs. To overcome these deficiencies, we introduce ’DebugBench’, an LLM debugging benchmark consisting of 4,253 instances. It covers four major bug categories and 18 minor types in C++, Java, and Python. To construct DebugBench, we collect code snippets from the LeetCode community, implant bugs into source data with GPT-4, and assure rigorous quality checks. We evaluate two commercial and four open-source models in a zero-shot scenario. We find that (1) while closed-source models exhibit inferior debugging performance compared to humans, open-source models relatively lower pass rate scores; (2) the complexity of debugging notably fluctuates depending on the bug category; (3) incorporating runtime feedback has a clear impact on debugging performance which is not always helpful. As an extension, we also compare LLM debugging and code generation, revealing a strong correlation between them for closed-source models. These findings will benefit the development of LLMs in debugging.
@inproceedings{tian2024debugbench, title = {DebugBench: Evaluating Debugging Capability of Large Language Models}, author = {Tian*, Runchu and Ye*, Yining and Qin, Yujia and Cong, Xin and Lin, Yankai and Pan, Yinxu and Wu, Yesai and Hui, Haotian and Liu, Weichuan and Liu, Zhiyuan and Sun, Maosong}, year = {2024}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2024}, } - ACL’25
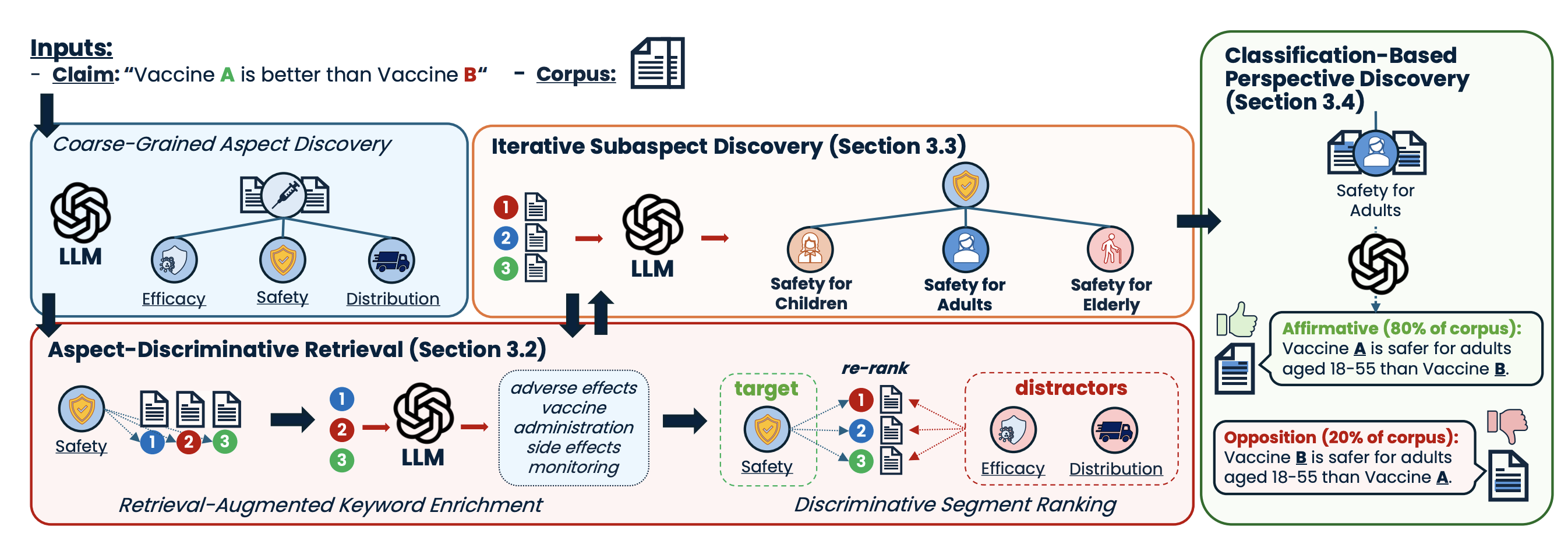 Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced ClaimsIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics
Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced ClaimsIn Proceedings of the 63rd Annual Meeting of the Association for Computational LinguisticsClaims made by individuals or entities are oftentimes nuanced and cannot be clearly labeled as entirely "true" or "false"—as is frequently the case with scientific and political claims. However, a claim (e.g., "vaccine A is better than vaccine B") can be dissected into its integral aspects and sub-aspects (e.g., efficacy, safety, distribution), which are individually easier to validate. This enables a more comprehensive, structured response that provides a well-rounded perspective on a given problem while also allowing the reader to prioritize specific angles of interest within the claim (e.g., safety towards children). Thus, we propose ClaimSpect, a retrieval-augmented generation-based framework for automatically constructing a hierarchy of aspects typically considered when addressing a claim and enriching them with corpus-specific perspectives. This structure hierarchically partitions an input corpus to retrieve relevant segments, which assist in discovering new sub-aspects. Moreover, these segments enable the discovery of varying perspectives towards an aspect of the claim (e.g., support, neutral, or oppose) and their respective prevalence (e.g., "how many biomedical papers believe vaccine A is more transportable than B?"). We apply ClaimSpect to a wide variety of real-world scientific and political claims featured in our constructed dataset, showcasing its robustness and accuracy in deconstructing a nuanced claim and representing perspectives within a corpus. Through real-world case studies and human evaluation, we validate its effectiveness over multiple baselines.
@inproceedings{kargupta2025beyond, title = {Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced Claims}, author = {Kargupta*, Priyanka and Tian*, Runchu and Han, Jiawei}, year = {2025}, booktitle = {Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics}, } - TMLR
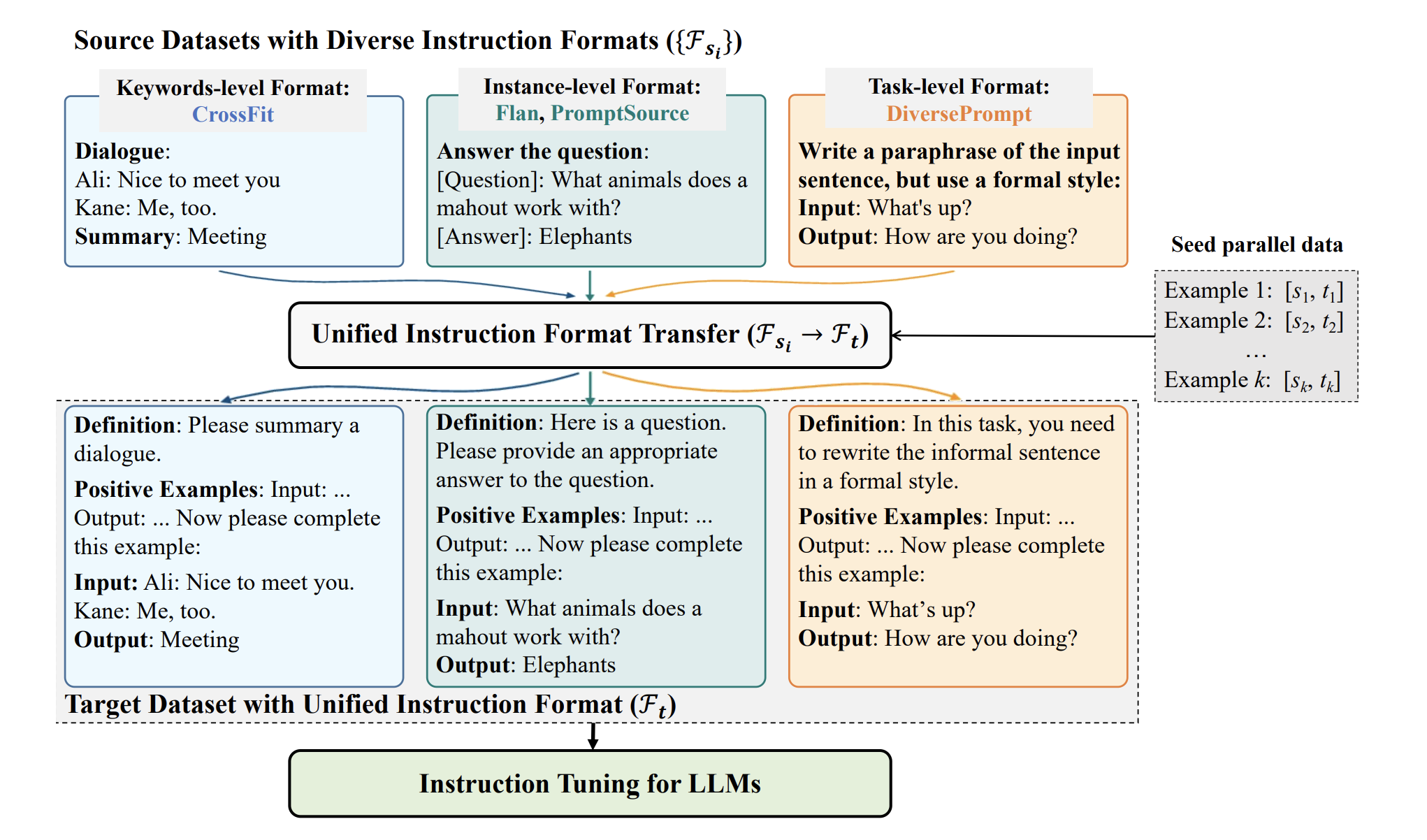 Exploring Format Consistency for Instruction TuningShihao Liang*, Runchu Tian*, Kunlun Zhu*, Yujia Qin, Huadong Wang, Xin Cong, Zhiyuan Liu, Xiaojiang Liu, and Maosong Sun
Exploring Format Consistency for Instruction TuningShihao Liang*, Runchu Tian*, Kunlun Zhu*, Yujia Qin, Huadong Wang, Xin Cong, Zhiyuan Liu, Xiaojiang Liu, and Maosong Sun
*Equal contributionTransactions on Machine Learning ResearchInstruction tuning has emerged as a promising approach to enhancing large language models in following human instructions. It is shown that increasing the diversity and number of instructions in the training data can consistently enhance generalization performance, which facilitates a recent endeavor to collect various instructions and integrate existing instruction tuning datasets into larger collections. However, different users have their unique ways of expressing instructions, and there often exist variations across different datasets in the instruction styles and formats, i.e., format inconsistency. In this work, we propose a framework named Unified Instruction Tuning (UIT), which calls OpenAI APIs for automatic format transfer among different instruction tuning datasets such as PromptSource, FLAN and CrossFit. With the framework, we (1) demonstrate the necessity of maintaining format consistency in instruction tuning; (2) improve the generalization performance on unseen instructions on T5-LM-xl; (3) provide a novel perplexity-based denoising method to reduce the noise of automatic format transfer to make the UIT framework more practical and a smaller offline model based on GPT-J that achieves comparable format transfer capability to OpenAI APIs to reduce costs in practice. Further analysis regarding variations of targeted formats and other effects is intended.
@article{liang2024exploring, title = {Exploring Format Consistency for Instruction Tuning}, author = {Liang*, Shihao and Tian*, Runchu and Zhu*, Kunlun and Qin, Yujia and Wang, Huadong and Cong, Xin and Liu, Zhiyuan and Liu, Xiaojiang and Sun, Maosong}, journal = {Transactions on Machine Learning Research}, } - EMNLP’25
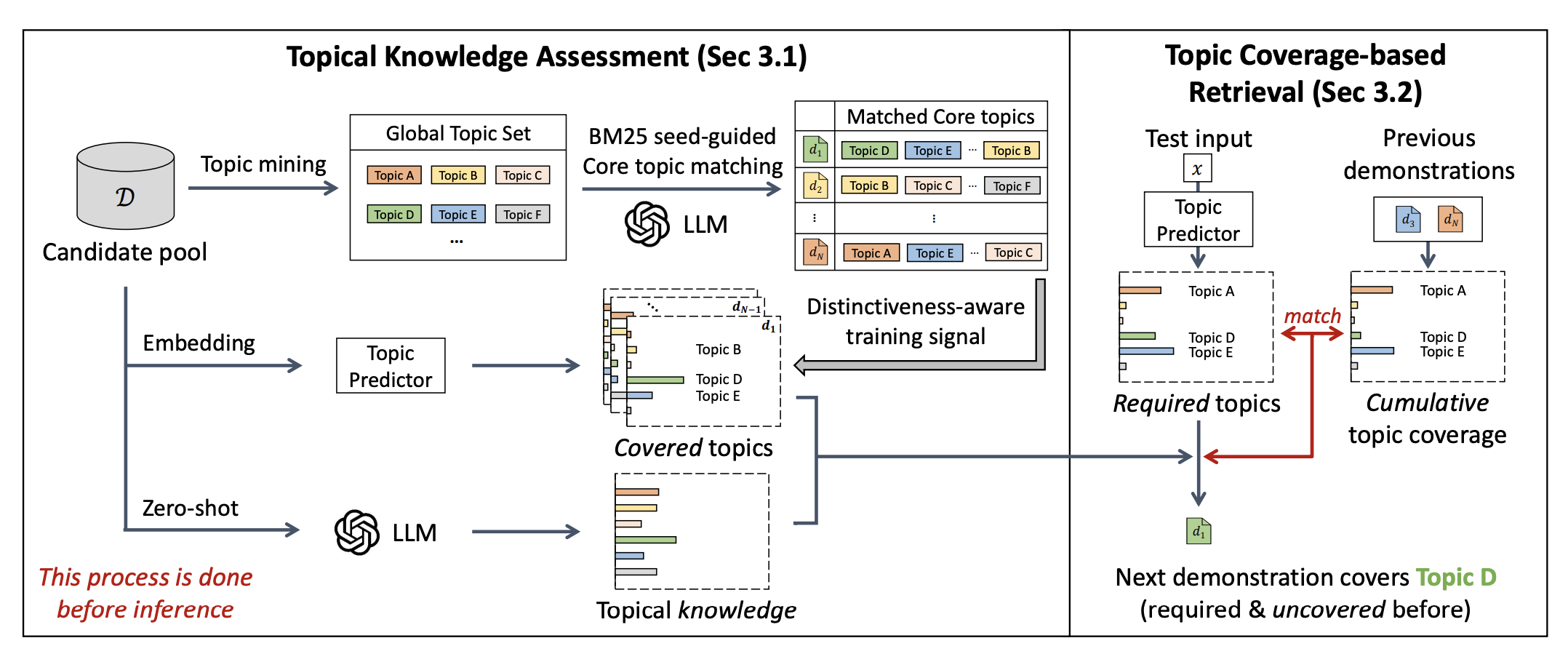 Topic Coverage-based Demonstration Retrieval for In-Context LearningIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Topic Coverage-based Demonstration Retrieval for In-Context LearningIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language ProcessingThe effectiveness of in-context learning relies heavily on selecting demonstrations that provide all the necessary information for a given test input. To achieve this, it is crucial to identify and cover fine-grained knowledge requirements. However, prior methods often retrieve demonstrations based solely on embedding similarity or generation probability, resulting in irrelevant or redundant examples. In this paper, we propose TopicK, a topic coverage-based retrieval framework that selects demonstrations to comprehensively cover topic-level knowledge relevant to both the test input and the model. Specifically, TopicK estimates the topics required by the input and assesses the model’s knowledge on those topics. TopicK then iteratively selects demonstrations that introduce previously uncovered required topics, in which the model exhibits low topical knowledge. We validate the effectiveness of TopicK through extensive experiments across various datasets and both open- and closed-source LLMs. Our source code is available at https://github.com/WonbinKweon/TopicK_EMNLP2025.
@inproceedings{kweon2025topic, title = {Topic Coverage-based Demonstration Retrieval for In-Context Learning}, author = {Kweon, Wonbin and Kang, SeongKu and Tian, Runchu and Jiang, Pengcheng and Han, Jiawei and Yu, Hwanjo}, year = {2025}, booktitle = {Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing}, } - COLM’25
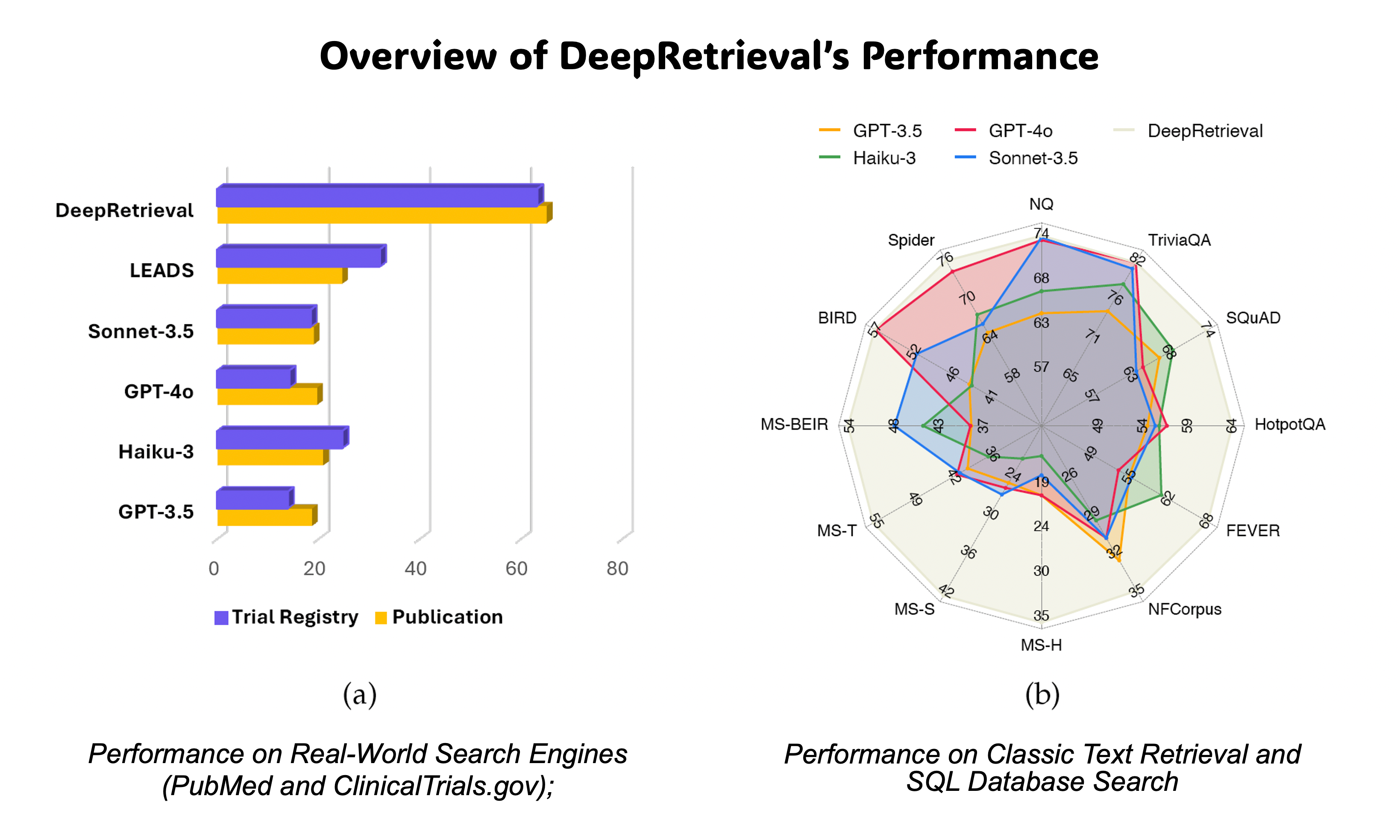 DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement LearningPengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei HanIn The Second Conference on Language Modeling
DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement LearningPengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei HanIn The Second Conference on Language ModelingInformation retrieval systems are crucial for enabling effective access to large document collections. Recent approaches have leveraged Large Language Models (LLMs) to enhance retrieval performance through query augmentation, but often rely on expensive supervised learning or distillation techniques that require significant computational resources and handlabeled data. We introduce DeepRetrieval, a reinforcement learning (RL) approach that trains LLMs for query generation through trial and error without supervised data (reference query). Using retrieval metrics as rewards, our system generates queries that maximize retrieval performance. DeepRetrieval outperforms leading methods on literature search with 65.07% (vs. previous SOTA 24.68%) recall for publication search and 63.18% (vs. previous SOTA 32.11%) recall for trial search using real-world search engines. DeepRetrieval also dominates in evidence-seeking retrieval, classic information retrieval and SQL database search. With only 3B parameters, it outperforms industry-leading models like GPT-4o and Claude-3.5-Sonnet on those tasks. These results demonstrate that our RL approach offers a more efficient and effective paradigm for information retrieval. Our data and code are available at: https://github.com/pat-jj/DeepRetrieval.
@inproceedings{jiang2025deepretrieval, title = {DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning}, author = {Jiang, Pengcheng and Lin, Jiacheng and Cao, Lang and Tian, Runchu and Kang, SeongKu and Wang, Zifeng and Sun, Jimeng and Han, Jiawei}, booktitle = {The Second Conference on Language Modeling}, year = {2025}, journal = {arXiv preprint arXiv: 2503.00223}, } - KDD’25
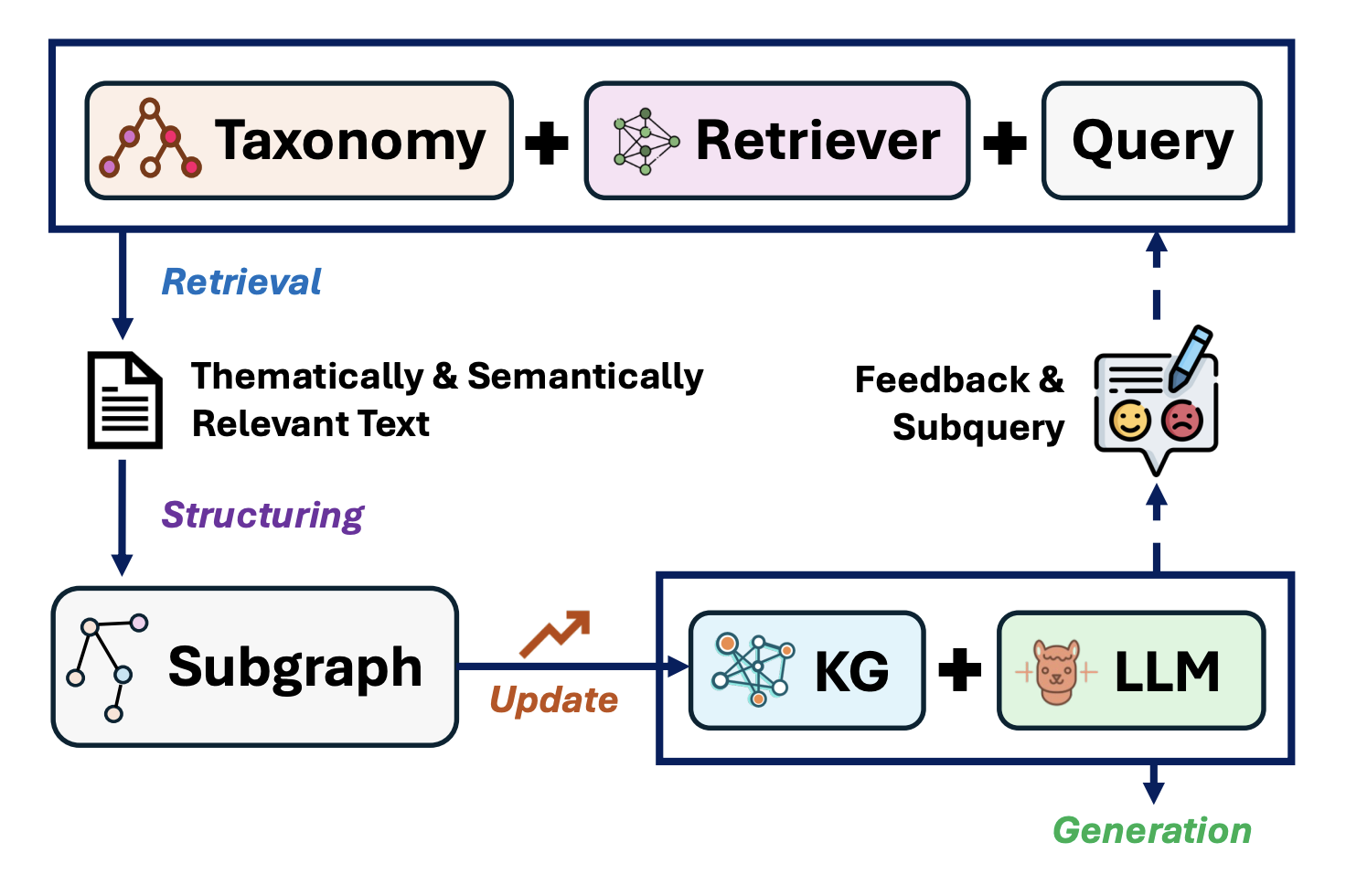 Retrieval and Structuring Augmented Generation with Large Language ModelsIn KDD ’25: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Retrieval and Structuring Augmented Generation with Large Language ModelsIn KDD ’25: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data MiningLarge Language Models (LLMs) have revolutionized natural language processing with their remarkable capabilities in text generation and reasoning. However, these models face critical challenges when deployed in real-world applications, including hallucination generation, outdated knowledge, and limited domain expertise. Retrieval And Structuring (RAS) Augmented Generation addresses these limitations by integrating dynamic information retrieval with structured knowledge representations. This survey (1) examines retrieval mechanisms including sparse, dense, and hybrid approaches for accessing external knowledge; (2) explore text structuring techniques such as taxonomy construction, hierarchical classification, and information extraction that transform unstructured text into organized representations; and (3) investigate how these structured representations integrate with LLMs through prompt-based methods, reasoning frameworks, and knowledge embedding techniques. It also identifies technical challenges in retrieval efficiency, structure quality, and knowledge integration, while highlighting research opportunities in multimodal retrieval, cross-lingual structures, and interactive systems. This comprehensive overview provides researchers and practitioners with insights into RAS methods, applications, and future directions.
@inproceedings{jiang2025retrieval, title = {Retrieval and Structuring Augmented Generation with Large Language Models}, author = {Jiang, Pengcheng and Ouyang, Siru and Jiao, Yizhu and Zhong, Ming and Tian, Runchu and Han, Jiawei}, booktitle = {KDD '25: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining}, year = {2025}, } - ICLR’24
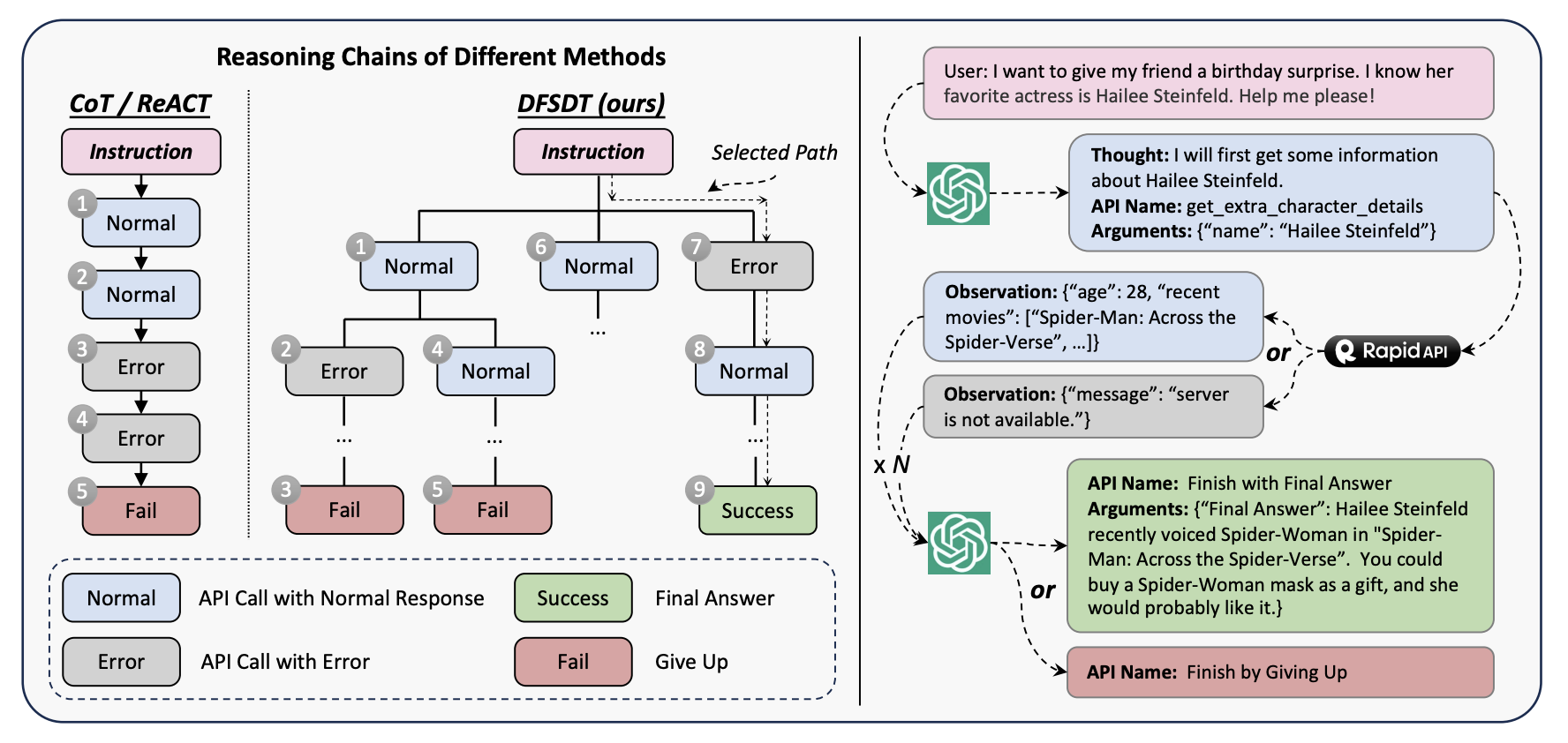 ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIsYujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong SunIn The Twelfth International Conference on Learning RepresentationsICLR’24 Spotlight
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIsYujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong SunIn The Twelfth International Conference on Learning RepresentationsICLR’24 SpotlightDespite the advancements of open-source large language models (LLMs), e.g., LLaMA, they remain significantly limited in tool-use capabilities, i.e., using external tools (APIs) to fulfill human instructions. The reason is that current instruction tuning largely focuses on basic language tasks but ignores the tool-use domain. This is in contrast to the excellent tool-use capabilities of state-of-the-art (SOTA) closed-source LLMs, e.g., ChatGPT. To bridge this gap, we introduce ToolLLM, a general tool-use framework encompassing data construction, model training, and evaluation. We first present ToolBench, an instruction-tuning dataset for tool use, which is constructed automatically using ChatGPT. Specifically, the construction can be divided into three stages: (i) API collection: we collect 16,464 real-world RESTful APIs spanning 49 categories from RapidAPI Hub; (ii) instruction generation: we prompt ChatGPT to generate diverse instructions involving these APIs, covering both single-tool and multi-tool scenarios; (iii) solution path annotation: we use ChatGPT to search for a valid solution path (chain of API calls) for each instruction. To enhance the reasoning capabilities of LLMs, we develop a novel depth-first search-based decision tree algorithm. It enables LLMs to evaluate multiple reasoning traces and expand the search space. Moreover, to evaluate the tool-use capabilities of LLMs, we develop an automatic evaluator: ToolEval. Based on ToolBench, we fine-tune LLaMA to obtain an LLM ToolLLaMA, and equip it with a neural API retriever to recommend appropriate APIs for each instruction. Experiments show that ToolLLaMA demonstrates a remarkable ability to execute complex instructions and generalize to unseen APIs, and exhibits comparable performance to ChatGPT. Our ToolLLaMA also demonstrates strong zero-shot generalization ability in an out-of-distribution tool-use dataset: APIBench.
@inproceedings{qin2024toolllm, title = {ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs}, author = {Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong}, booktitle = {The Twelfth International Conference on Learning Representations}, year = {2024}, } - CACM
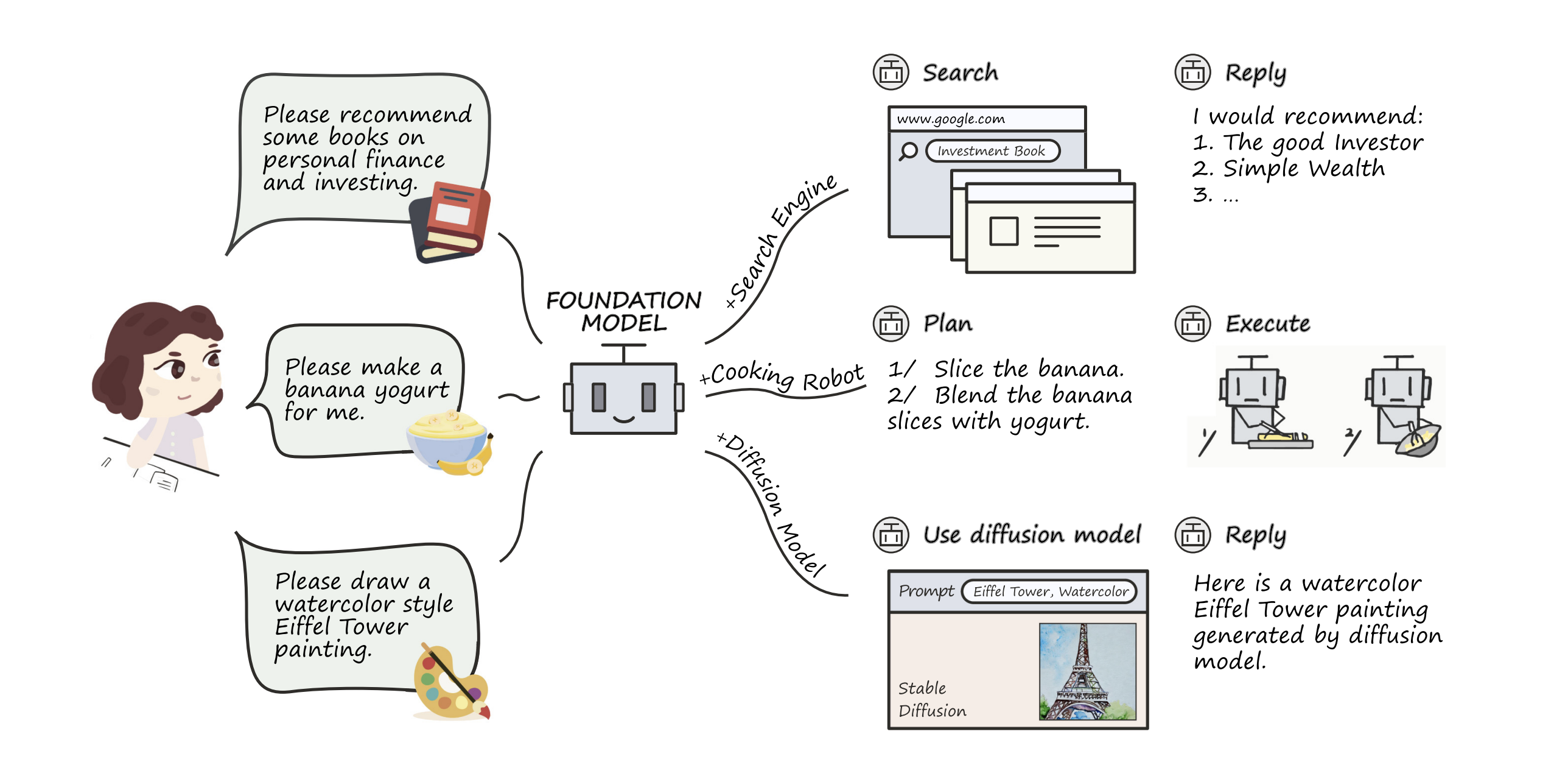 Tool Learning with Foundation ModelsYujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yuxiang Huang, Junxi Yan, Xu Han, Xian Sun, Dahai Li, Jason Phang, Cheng Yang, Tongshuang Wu, Heng Ji, Guoliang Li, Zhiyuan Liu, and Maosong SunACM Computing Surveys
Tool Learning with Foundation ModelsYujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yuxiang Huang, Junxi Yan, Xu Han, Xian Sun, Dahai Li, Jason Phang, Cheng Yang, Tongshuang Wu, Heng Ji, Guoliang Li, Zhiyuan Liu, and Maosong SunACM Computing SurveysHumans possess an extraordinary ability to create and utilize tools. With the advent of foundation models, artificial intelligence systems have the potential to be equally adept in tool use as humans. This paradigm, which is dubbed as tool learning with foundation models, combines the strengths of tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. This article presents a systematic investigation and comprehensive review of tool learning. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research and formulate a general framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each subtask by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate generalization in tool learning. Finally, we discuss several open problems that require further investigation, such as ensuring trustworthy tool use, enabling tool creation with foundation models, and addressing personalization challenges. Overall, we hope this article could inspire future research in integrating tools with foundation models.
@article{qin2024tool, title = {Tool Learning with Foundation Models}, author = {Qin, Yujia and Hu, Shengding and Lin, Yankai and Chen, Weize and Ding, Ning and Cui, Ganqu and Zeng, Zheni and Zhou, Xuanhe and Huang, Yufei and Xiao, Chaojun and Han, Chi and Fung, Yi Ren and Su, Yusheng and Wang, Huadong and Qian, Cheng and Tian, Runchu and Zhu, Kunlun and Liang, Shihao and Shen, Xingyu and Xu, Bokai and Zhang, Zhen and Ye, Yining and Li, Bowen and Tang, Ziwei and Yi, Jing and Zhu, Yuzhang and Dai, Zhenning and Yan, Lan and Cong, Xin and Lu, Yaxi and Zhao, Weilin and Huang, Yuxiang and Yan, Junxi and Han, Xu and Sun, Xian and Li, Dahai and Phang, Jason and Yang, Cheng and Wu, Tongshuang and Ji, Heng and Li, Guoliang and Liu, Zhiyuan and Sun, Maosong}, journal = {ACM Computing Surveys}, year = {2024}, }














Thank Patrick Jiang for the development of website template!